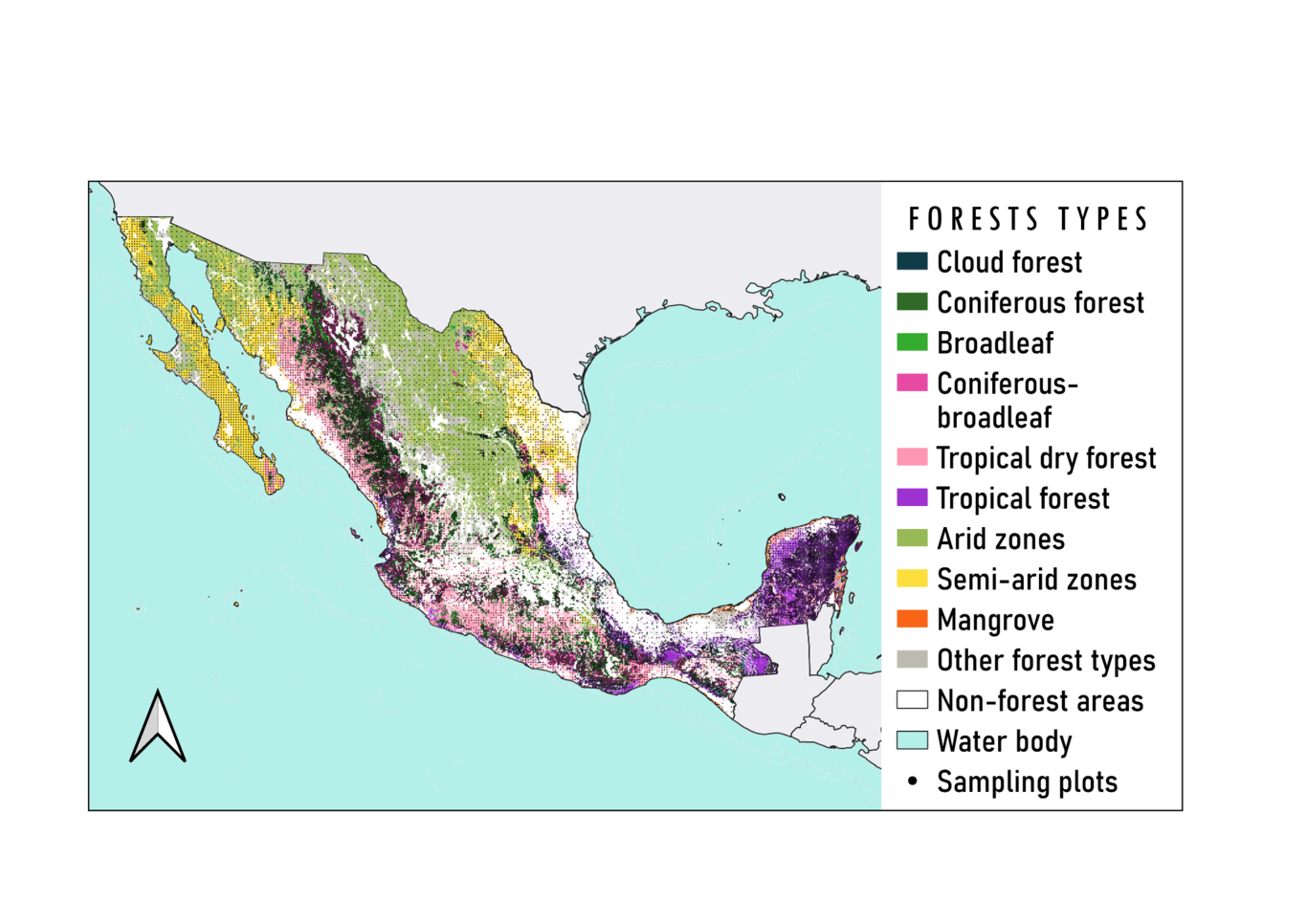
The National Forestry Commission of Mexico continuously monitors forest structure within the country’s continental territory by the implementation of the National Forest and Soils Inventory (INFyS). Due to the challenges involved in collecting data exclusively from field surveys, there are spatial information gaps for important forest attributes. This can produce bias or increase uncertainty when generating estimates required to support forest management decisions. Our objective is to predict the spatial distribution of tree height and tree density in all Mexican forests. We performed wall-to-wall spatial predictions of both attributes in 1-km grids, using ensemble machine learning across each forest type in Mexico. Predictor variables include remote sensing imagery and other geospatial data (e.g., vegetation indexes, surface temperature). Training data is from the 2009-2014 cycle (n>26,000 sampling plots). Spatial cross validation suggested that the model had a better performance when predicting tree height r2=0.4 [0.15,0.55] (mean[min, max]) than for tree density r2=0.2[0.10,0.31]. Maximum values of tree height were for coniferous forests, coniferous-broadleaf forests and cloud mountain forest (~36 m, 30 m and 21 m, respectively). Tropical forests had maximum values of tree density (~1370 trees/ha), followed by tropical dry forest (1006 trees/ha) and coniferous forest (988 trees/ha). Although most forests had relatively low values of uncertainty, e.g., values <40%, arid and semiarid ecosystems had high uncertainty in both tree height and tree density predictions, e.g., values >60%. The applied open science approach we present is easily replicable and scalable, thus it is helpful to assist in the decision-making and future of the National Forest and Soils Inventory. This work highlights the need for technical capabilities aimed to use and resignify all the effort done by the Mexican Forestry Commission in implementing the INFyS.