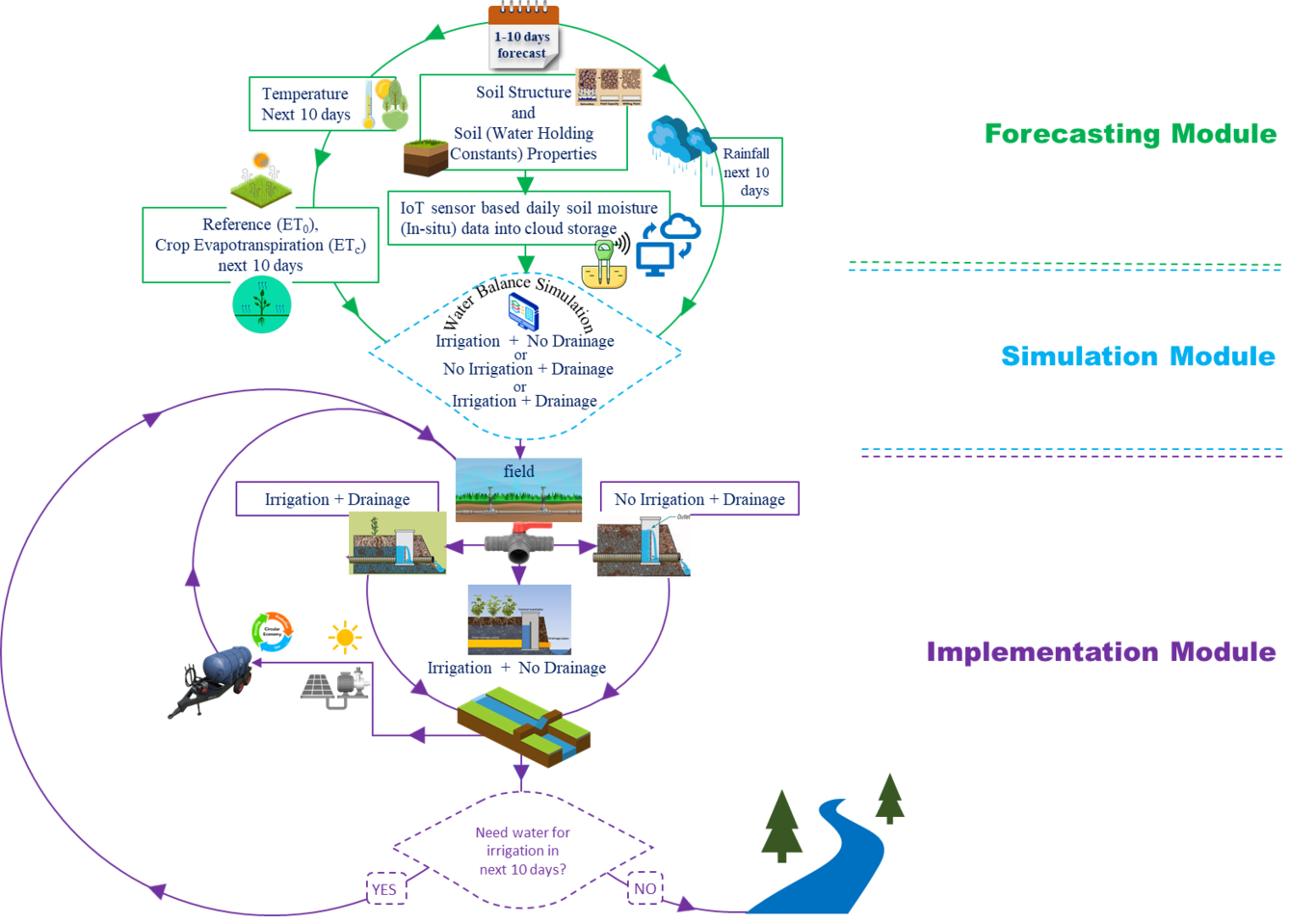
Smart drainage management to limit summer drought damage in Nordic agriculture under the circular economy conceptSyed Md Touhidul Mustafa 1, *, Kedar Ghag1, Anandharuban Panchanathan2, Bishal Dahal 1, Amirhossein Ahrari1, Toni Liedes 3, Hannu Marttila1, Tamara Avellán1, Mourad Oussalah2, Björn Klöve 1, & Ali Torabi Haghighi11Water, Energy and Environmental Engineering Research Unit, University of Oulu, P.O. Box 4300, FIN90014, Oulu, Finland2Center for Machine Vision and Signal Analysis, University of Oulu, Finland3Intelligent Machines and Systems, University of Oulu, PO Box 4200, 90014 Oulu, Finland