AUTHOREA
Log in
Sign Up
Browse Preprints
LOG IN
SIGN UP
Alyssa Goodman
Professor
Cambridge, MA
Member of:
Harvard-Smithsonian Center for Astrophysics (CFA)
Harvard University
Public Documents
7
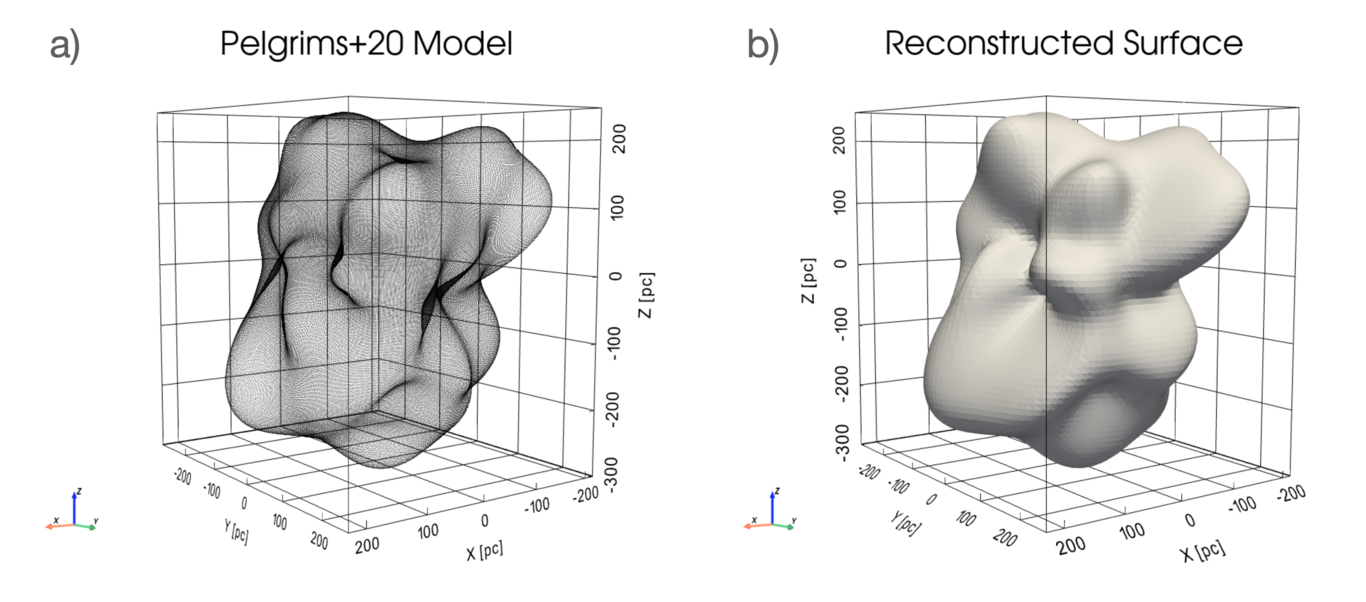
The Bones of the Milky Way
Alyssa Goodman, João Alves, Robert A Benjamin, et al.
March 07, 2023
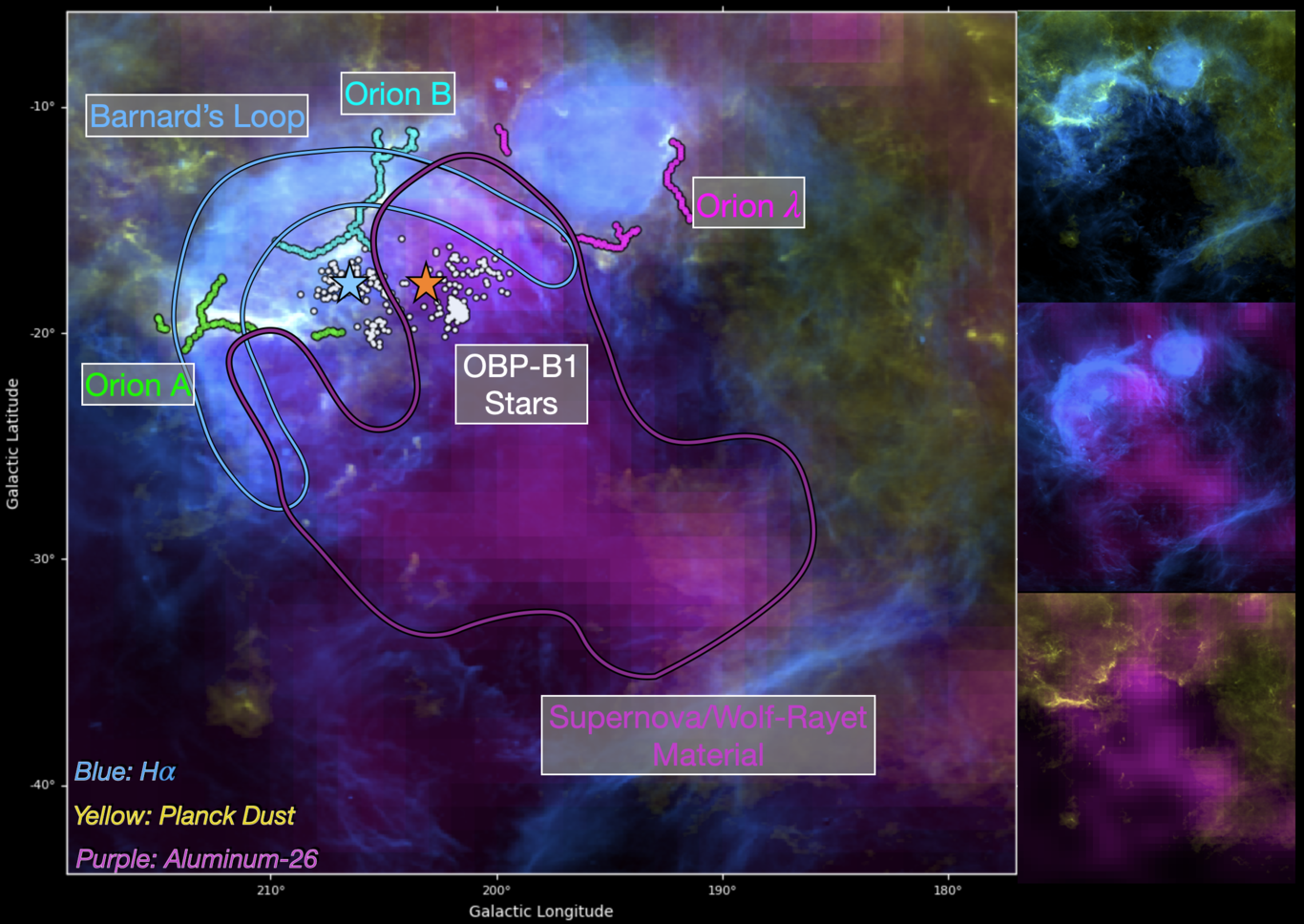
A 3D View of Orion: I. Barnard’s Loop
Michael Foley, Catherine Zucker, Alyssa Goodman, et al.
January 11, 2023
Mapping the Local Bubble's Magnetic Field in 3D
Theo O'Neill, Alyssa Goodman, Juan Soler, et al.
February 15, 2022
Curriculum Vitae: Alyssa A. Goodman
Alyssa Goodman
January 17, 2021
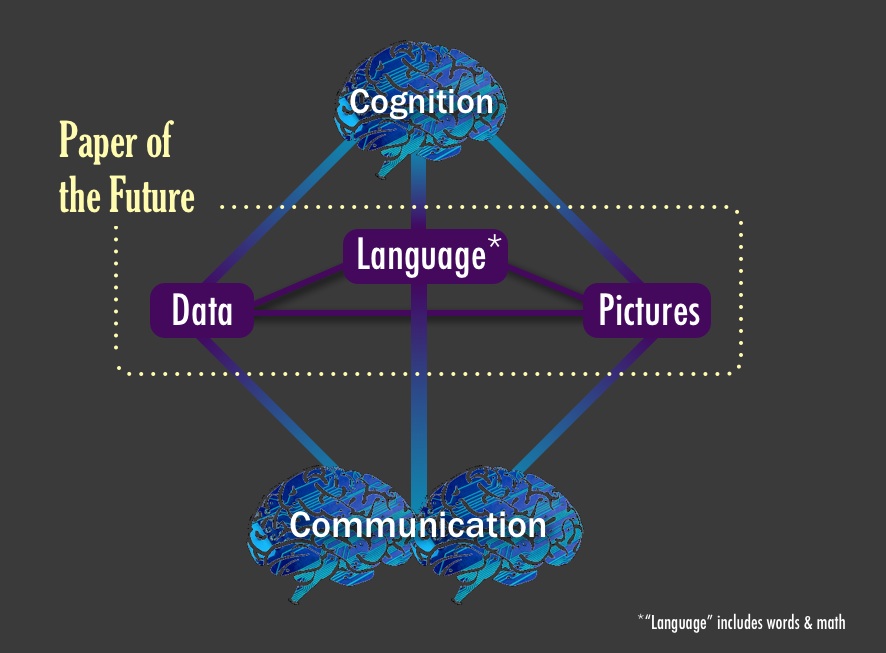
The "Paper" of the Future
Alyssa Goodman, Josh Peek, Alberto Accomazzi, et al.
10 Simple Rules for the Care and Feeding of Scientific Data
Alberto Pepe and Alyssa Goodman
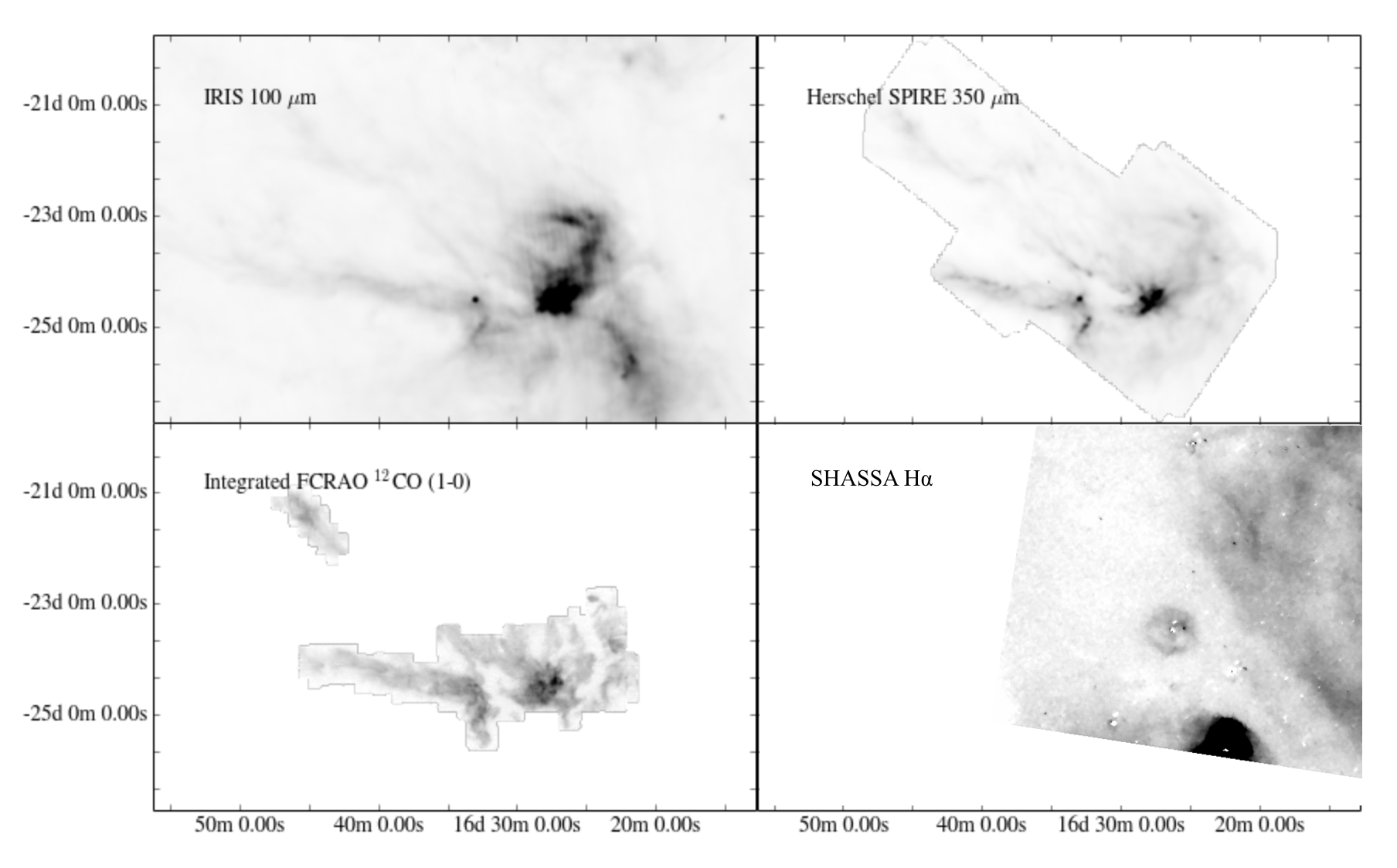
Effects of an Embedded B-star Wind on the Properties of the Near-by Cloud: Ophiuchus
Hope How-Huan Chen and Alyssa Goodman