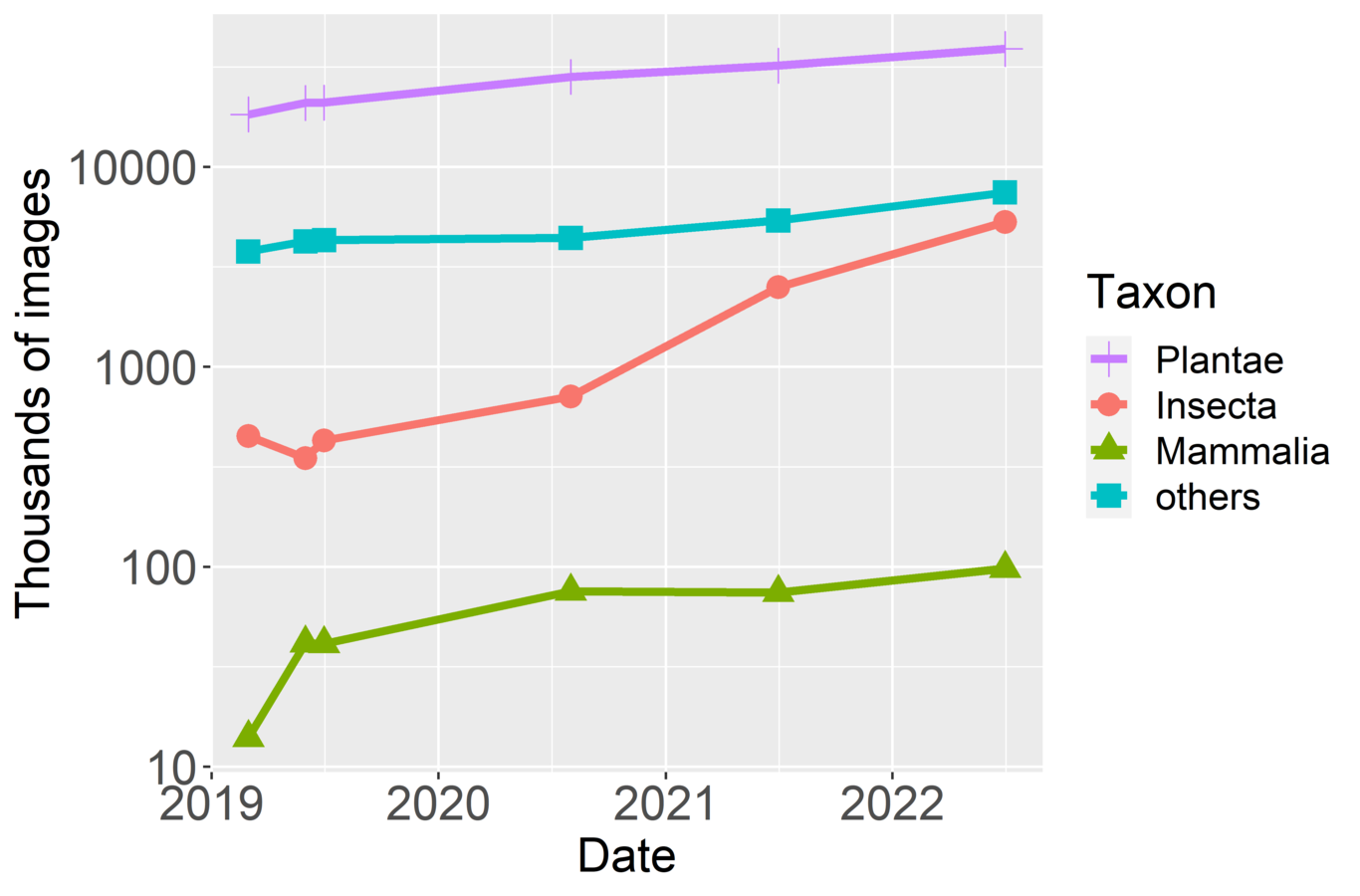
AbstractTens of millions of images from biological collections have become available online in the last two decades. In parallel, there has been a dramatic increase in the capabilities of image analysis technologies, especially those involving machine learning and computer vision. Whilst image analysis has become mainstream in consumer applications, it is still only used on an artisanal basis in the biological collections community, largely because the image corpora are dispersed. Yet, there is massive untapped potential for novel applications and research if the images of collection objects could be made accessible as a single corpus. In this paper, we make the case for building infrastructure that could support image analysis of collection objects. We show that such an infrastructure is entirely feasible and well worth the investment.IntroductionOwing to their central role in cataloguing the world’s biodiversity, global biological collections likely hold samples of most known macro-biodiversity. As such, they are an irreplaceable asset for research of all kinds, including ecology, conservation, natural history and epidemiology \cite{Bradley_2014,Cook_2014,Davis_2019,Antonelli_2020}. They are also seen as an important and underused resource to address numerous questions in the context of biodiversity under global change \cite{Soltis_2017,Meineke_2018,Hussein_2022}. Thus ensuring access to, and integrating data from these collections is globally important for the future. Conservation and sustainable use of biodiversity are fundamental to the 2030 Agenda of the \cite{secretariat_of_the_convention_on_biological_diversity_biodiversity_2016} and achieving its sustainable development goals is only realistic with the collections that underpin accurate naming and knowledge of biodiversity.To keep pace with the demand for access to collections, digital imaging of biological collections has progressed at pace (Fig. 1). As of September 2022, the Global Biodiversity Information Facility (GBIF) has more than 49 million preserved or fossil specimens with an image. For just the nearly 400 million specimens of plants held in collections globally \cite{thiers_worlds_2020}, there are almost 38 million (9%) occurrences with images on GBIF. This number is expected to grow substantially. For example, the digitisation of the Kew herbarium, which holds over 7 million specimens will add to already major digitization programs in Australia, China, Europe and the United States among others \cite{willis_science_2018,Nelson_2018,Borsch_2020,chinese_virtual_herbarium_299000_2021}.\ref{240550}\ref{205447}