AUTHOREA
Log in
Sign Up
Browse Preprints
LOG IN
SIGN UP
Jinkinson Smith
Atlanta, Georgia
Member of:
PREreview
Public Documents
4
August 06, 2020
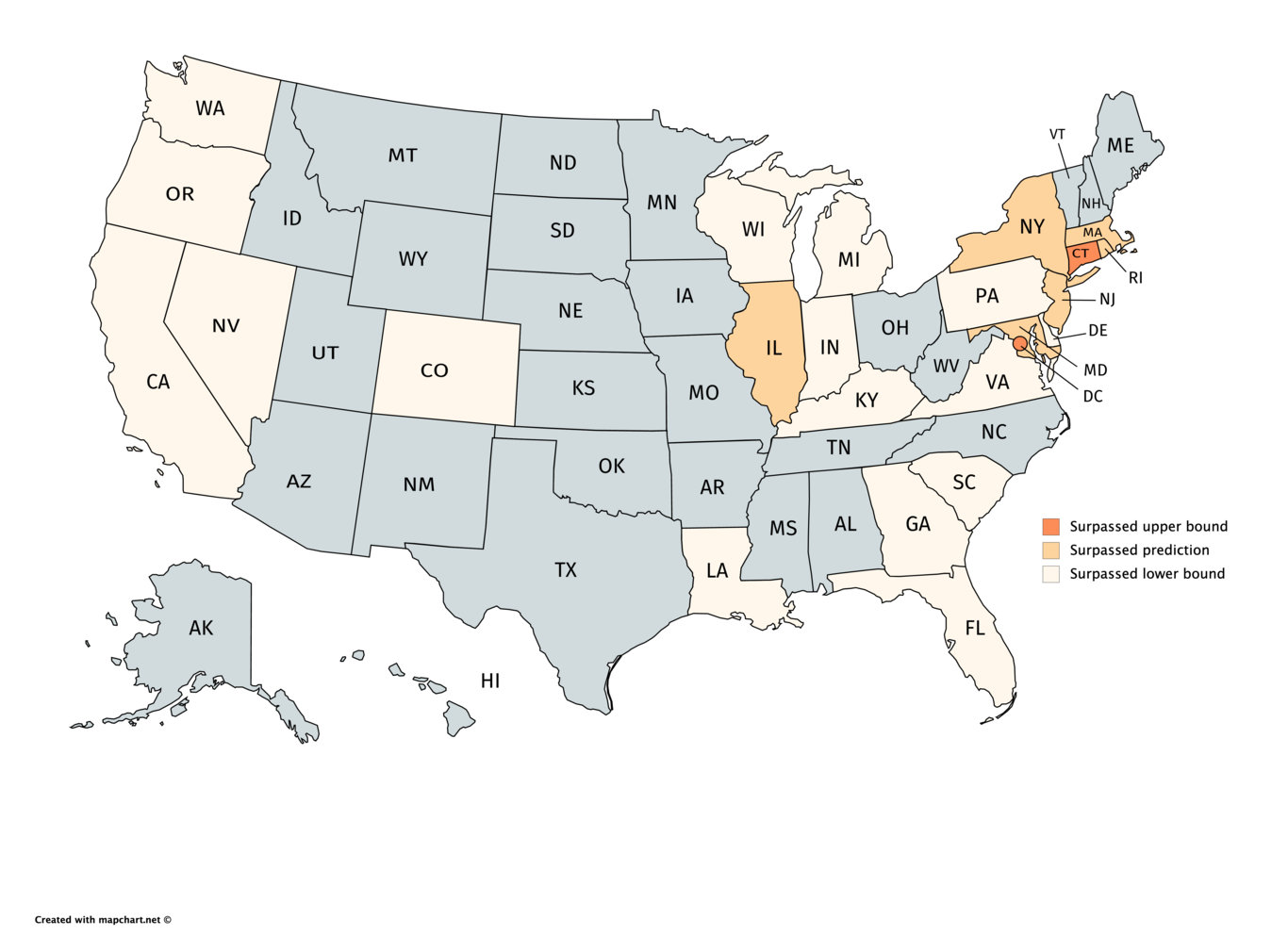
Comparing the IHME COVID-19 health service utilization forecasting team's predicted c...
Jinkinson Smith
June 14, 2021
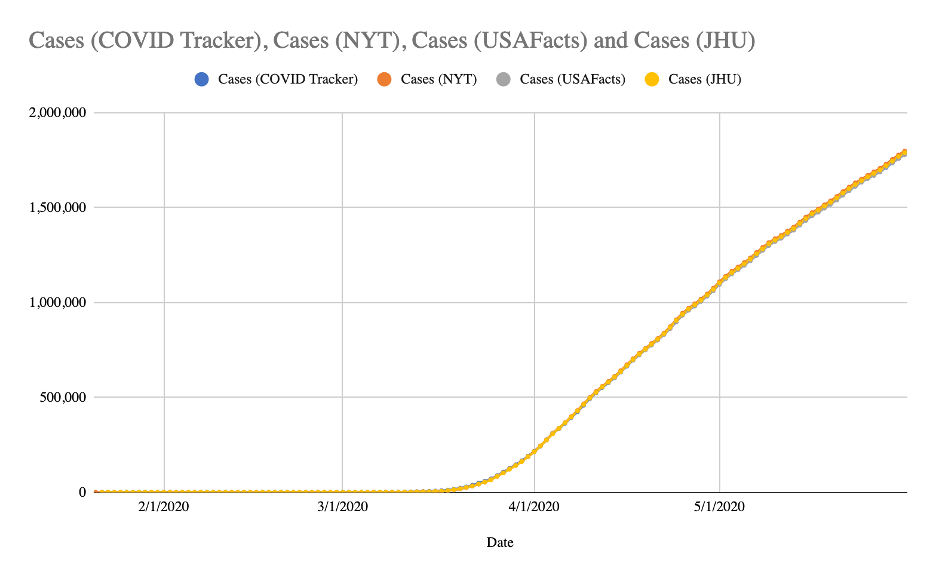
Comparison of COVID-19 case and death counts in the United States reported by four on...
Jinkinson Smith
August 06, 2020
The debate over twin studies: an overview
Jinkinson Smith
June 13, 2019
Genome-wide association studies of intelligence: a review of the literature
Jinkinson Smith