AUTHOREA
Log in
Sign Up
Browse Preprints
LOG IN
SIGN UP
Markus Luczak-Roesch
Public Documents
2
May 07, 2018
A Working Definition of Online Citizen Science
Cathal Doyle, Markus Luczak-Roesch, Yevgeniya Li, et al.
April 21, 2018
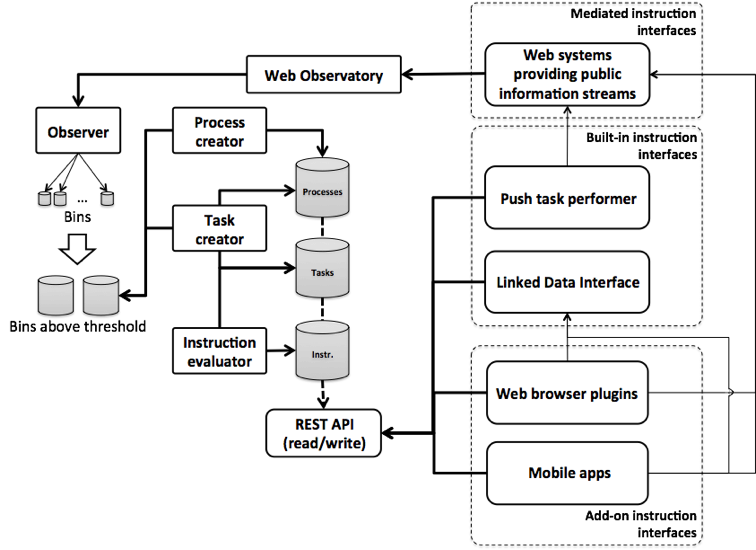
Anatomy of a Social Computer
Markus Luczak-Roesch, Ramine Tinati, Saud Aljaloud, et al.