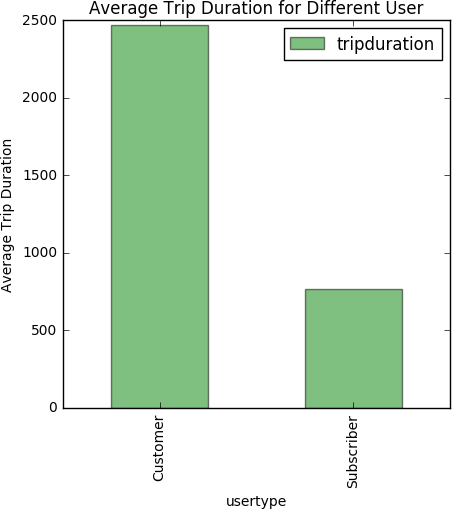
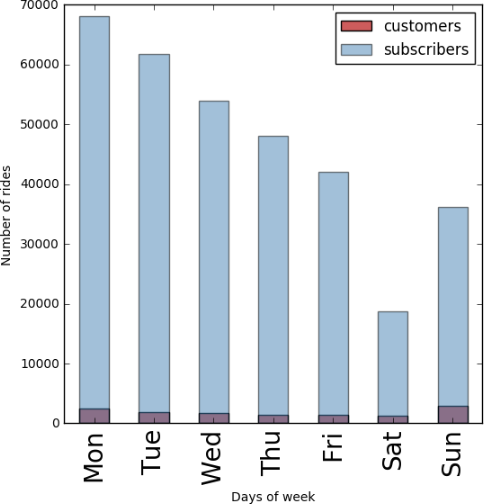
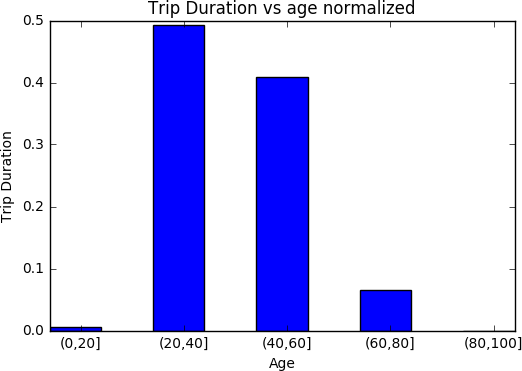
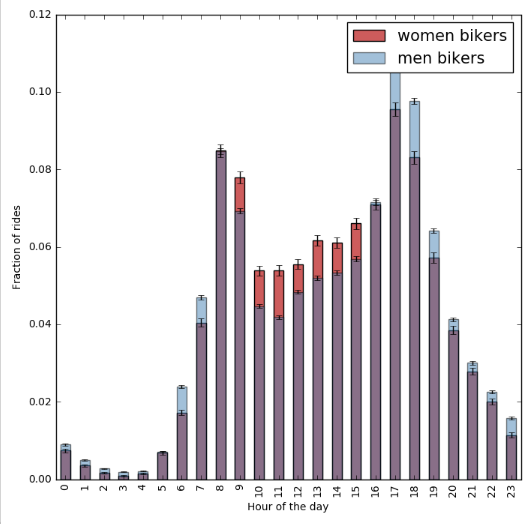
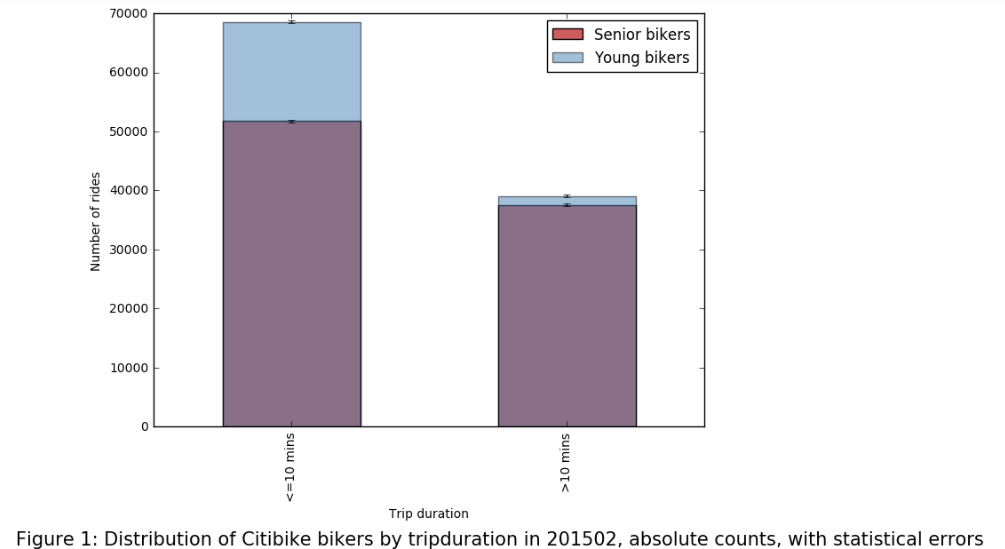
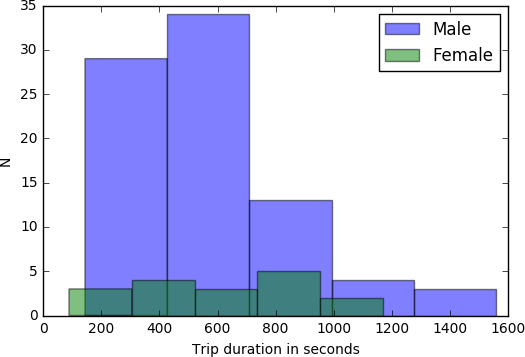
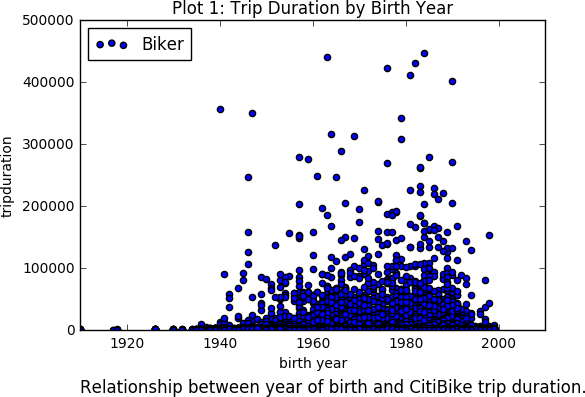
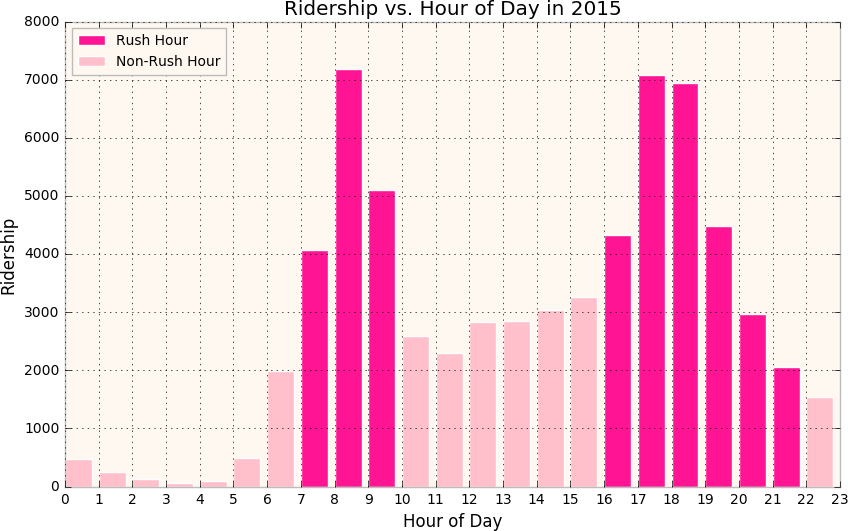
ABSTRACT New York City keeps records of Citi Bike services, including demographics of users and statistics on bike use. Here, we performed a statistical analysis to determine the relationship between biker age and trip duration, testing the alternative hypothesis that Citi Bike users under age 35 are more likely to bike for longer durations than the average user. Through a simple Z-test, we were able to reject our null hypothesis, concluding that trip duration of bikers under 35 is significantly greater than the average user. DATA For this project, our research question was: _Are Citi Bike users under 35 years of age significantly more likely bike for longer durations compared to the average user?_ For this analysis, we formed the following hypotheses: _Null Hypothesis:_ The mean trip duration of Citi Bike users under the age of 35 is the same or less than the mean trip duration of an average user, significance level = 0.05. _Alternative Hypothesis:_ The mean trip duration of Citi Bike users under the age of 35 is more than the mean trip duration of an average user, significance level = 0.05 To test these hypotheses, we chose Citi Bike data from December 2015. The information downloaded from the data facility contained more variables than needed to compare age and trip duration. Additionally, it was not organized in columns, which could led to errors, such as interpreting variable names as observations. As such, we first organized our data into columns, then dropped 13 of the 15 categories. We were left with “birth year” as our independent variable, and “trip duration” in seconds as our dependent variable. After plotting both variables, we identified several outliers of impossibly old users, i.e., those born before 1910. Plot 1 shows a scatter plot of the raw data, plotting birth year against trip duration. Histogram 1 shows the raw distribution of age across the data set. In Histogram 3, the distributions of trip duration for the entire data set (in blue) and for the group of those 35 and under (in green) are compared. ANALYSIS Our peer reviews suggested we perform a Z-test to compare the information of users under 35 and the total population. This test is possible because we know the population parameters (since dataset itself represents the entire population of Citi Bike users). Given the size of our sample, and the fact that we know the mean and standard deviation for both both groups, we chose to test our hypothesis with a Z-test. As such, we first had to calculate the mean and standard trip duration for the two groups. These values were plugged into the Z-test formula. RESULTS From our Z-test, we obtained a Z-statistic of 17.79. From the Z-Table, this gave an area of over 0.9998. Thus, our p-value is (1 - 0.9998), or 0.0002, meaning there is a 0.02% probability that the difference observed between the two groups is due to chance alone. Specifically, this p-value is much smaller than our alpha level of 0.05, meaning we can reject our null hypothesis, and can conclude that trip duration times of Citi Bike users are longer for those under age 35 compared the average user. LINK TO ORIGINAL NOTEBOOK https://github.com/jc7344/PUI2016_jc7344/blob/master/HW6_jc7344/HW6_Assignment2.ipynb