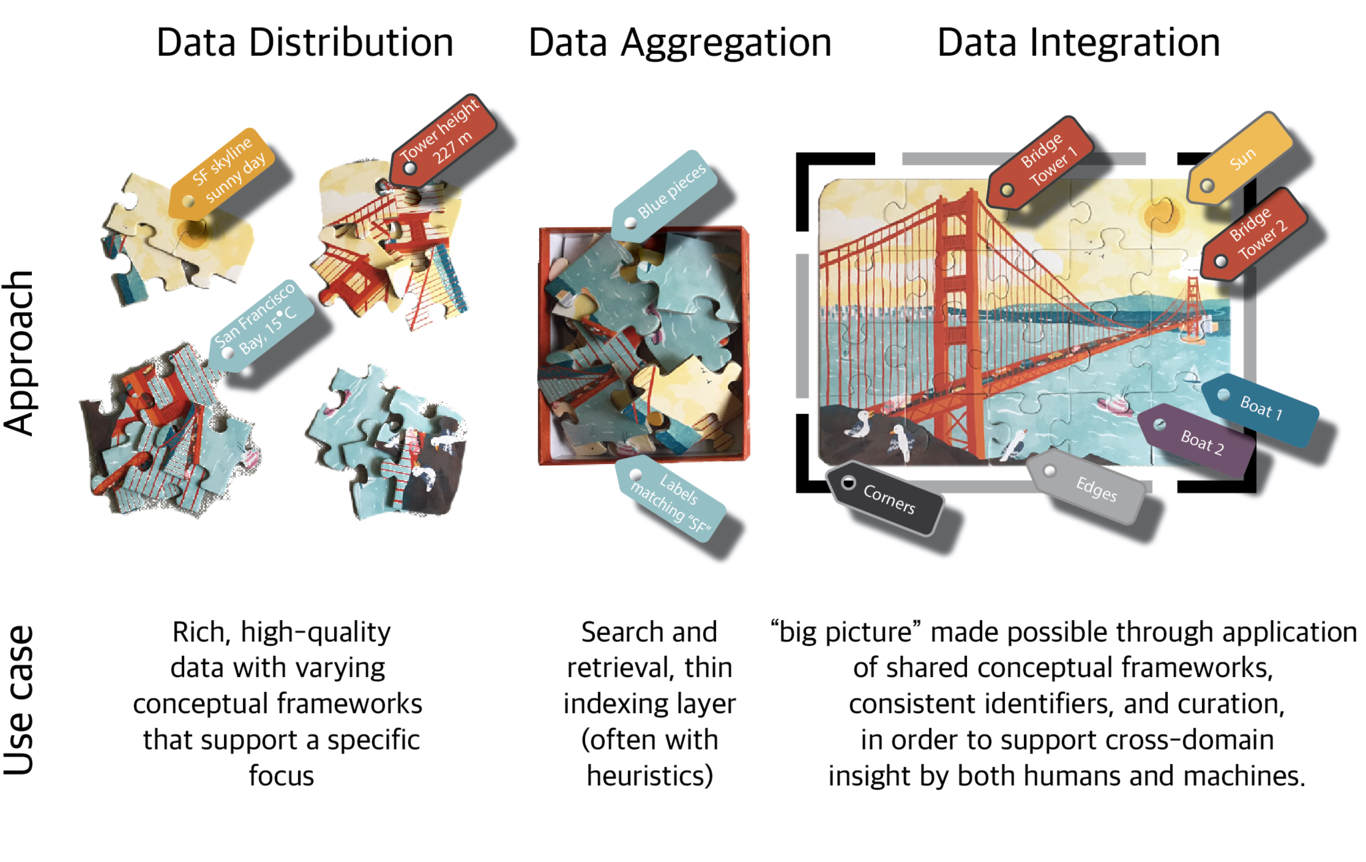
As appearing on eLife LabsAuthors: Lilly Winfree, Julie McMurry, Melissa HaendelThe Monarch Initiative is an international consortium, comprised of an eclectic mix of biologists, ontologists, programmers, geneticists, and clinicians; we take disparate genetic and phenotypic data and integrate it for disease discovery and diagnosis. Towards this end, we have developed a web portal (https://monarchinitiative.org) and numerous tools and new APIs that we want to share with scientists across disciplines.At Monarch, the data we are unifying is diverse and describes fundamentally different kinds of observations. Our integrated data corpus currently contains data from 35+ sources and 100+ genuses, and is composed of different data types such as genetic expression and variation, disease associations, different kinds of phenotypes, and is represented together with the type of evidence that supports it (e.g. a PMID, a traceable author statement, or a genetic sequence similarity score). But we don’t only integrate the data - we also provide more complex algorithmic associations, such as phenotypic enrichment or statistical modeling, all with a goal of illuminating new connections between this data.Why are we concerned with programmatically and computationally integrating this data? As an example use case, take a physician with a patient diagnosed with Fanconi Anemia (FA). The physician is interested in a new potential treatment, and is searching the internet for literature related to FA using the patient’s symptoms of “skeletal anomalies of the hips, spine” as keywords. However, this same feature of FA is described as “kinked tail” in mouse models of FA, resulting in reduced literature search results for the physician, and therefore less knowledge transfer. In our ideal world, the physician would search over our integrated data on our WebPortal and find relevant data that would include information from humans and other models, and that integrated data could better inform the physician.However, integrating this data is easier said than done. Each piece of data can be thought of as a puzzle piece; it contains various colors and contours, but it is difficult to see the big picture without assembling all the puzzle pieces. The purpose of data integration is insight, not raw connections. When integrating data, we first aggregate all the data, but this alone is insufficient to solve the puzzle. To fully integrate this data, we cannot simply dump all the puzzle pieces together; we must assemble them in the correct order. However, this assembly can be very difficult without the right model.