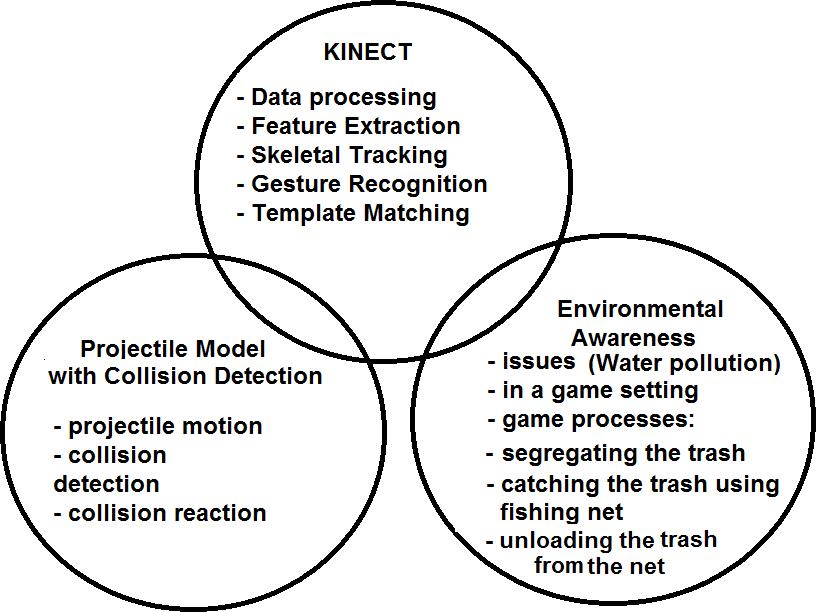
Abstract The Protector of the Sea is a gesture-based game with a concept of environmental awareness that examines each user’s gestures to qualify for collision detection. The system focuses on assessing the accuracy of the gesture recognition through testing methods, providing questionnaire for an overall feedback with a rating of 4 being Strongly Agree and 1 being Strong Disagree, and calculating paired T-distribution statistics for the learning of the system through a questionnaire given to the same set of users before and after the game. Although there are existing approaches for gesture recognition that provides a relatively accurate feedback for the gestures, none had utilized collision detection for recognition. Usage of the system shows that it was an interesting and knowledgeable for the users. Alongside, it also provides entertainment and uniqueness to the users. The researchers see this study as significant to those who would like to explore gesture recognition using motion capture devices using a similar approach in the future. Forty-five (45) users from grade levels 7, 9, 10 and Alternative Learning Students (ALS) participated in the study, each of them played the game. These users’ gestures were assessed and evaluated all throughout the game. Seven different gestures were characterized from the system, namely, Catch Right, Catch Middle, Catch Left, Catch Right Forward, Catch Middle Forward, Catch Left Forward and Unload. Based on the results of the testing, the system performed 85.73% accuracy. The overall rating of the system produced was 84%. The calculated result t of -5.6552, and the critical value, 2.015 of the statistical test showed that the means of the before and after data has a significant difference in the existing knowledge of the users’ before and after the game was presented. Keywords: collision detection, environmental awareness, gesture, recognition, 3d motion capture, technology, Kinect