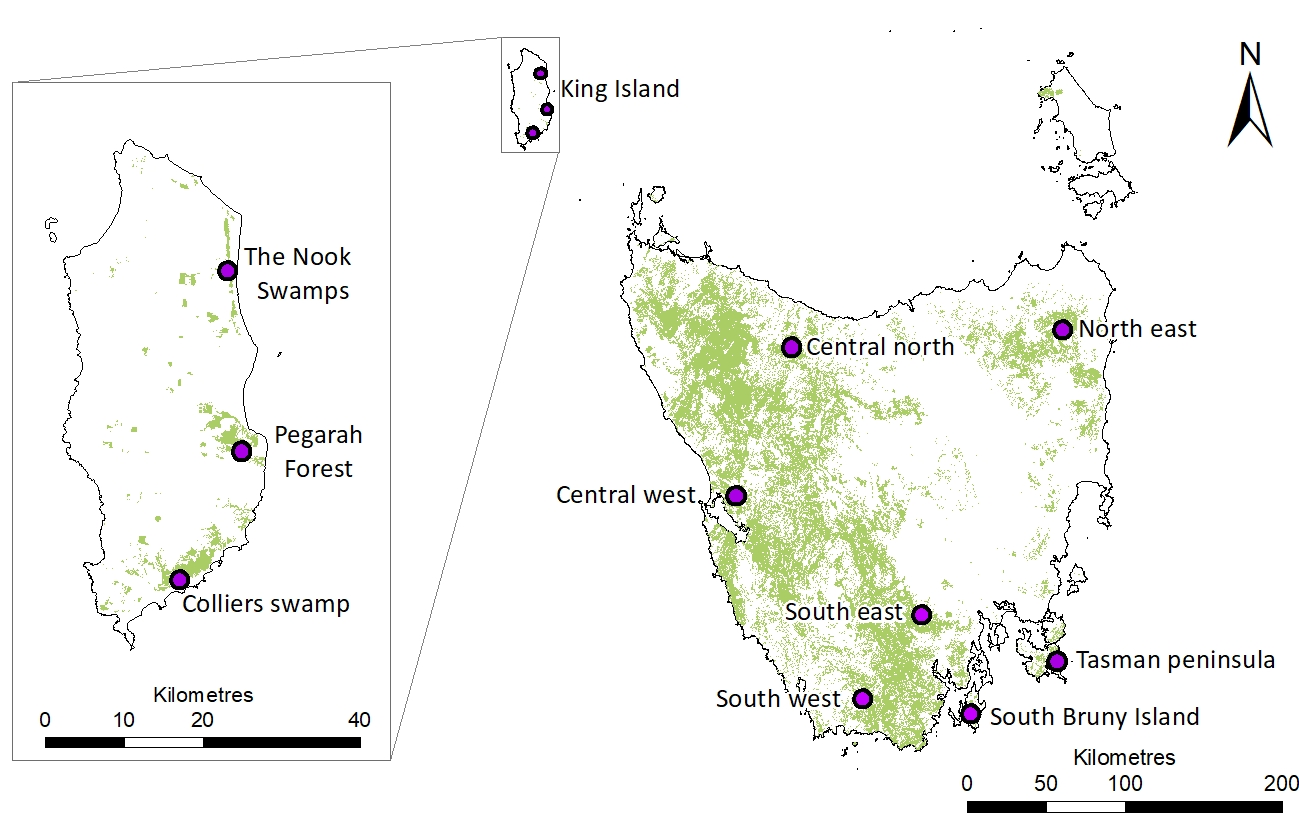
TITLE : Genomic insights into a critically endangered island endemic songbird provide a roadmap for preventing extinction.RUNNING TITLE: King Island Scrubtit conservation genetics.AUTHORS : Ross Crates1¶, Brenton von Takach2, Catherine M Young1, Dejan Stojanovic1, Linda Neaves1, Liam Murphy1, Daniel Gautschi1, Carolyn J. Hogg3,4, Robert Heinsohn1, Phil Bell5, Katherine A. Farquharson3,4.1. Fenner School of Environment and Society, Australian National University, Linnaeus Way, Acton, Canberra 2601.2. School of Molecular and Life Sciences, Curtin University, Bentley, Perth, Western Australia 6102.3. The University of Sydney, School of Life and Environmental Sciences, NSW 2006, Australia4. Australian Research Council Centre of Excellence for Innovations in Peptide and Protein Science, The University of Sydney, NSW 2006, Australia5. Biological Sciences, School of Natural Sciences, University of Tasmania, Hobart, Tasmania, 7005, Australia¶Corresponding Author: [email protected]: Small, fragmented or isolated populations are at risk of population decline due to fitness costs associated with inbreeding and genetic drift. The King Island scrubtit Acanthornis magna greeniana is a critically endangered endemic subspecies of the nominate Tasmanian scrubtit Acanthornis magna magna, with an estimated population of <100 individuals persisting in three patches of swamp forest. The Tasmanian scrubtit is widespread in wet forests on mainland Tasmania. We sequenced the scrubtit genome using PacBio HiFi and undertook a population genomics study of the King Island and Tasmanian scrubtit using a double-digest restriction site-associated DNA (ddRAD) dataset of 5,239 SNP loci. The genome was 1.48 Gb long, comprising 1,518 contigs with an N50 of 7.715 Mb. King Island scrubtits formed one of four overall genetic clusters, but separated into three distinct subpopulations when analysed separately. Pairwise FST values were greater among the King Island scrubtit subpopulations than among most Tasmanian scrubtit subpopulations. Genetic diversity was lower and inbreeding coefficients were higher in the King Island scrubtit than all except one of the Tasmanian scrubtit subpopulations. We observed crown baldness in 8/15 King Island scrubtits, but 0/55 Tasmanian scrubtits. Six loci were significantly associated with baldness, including one within the DOCK11 gene which is linked to early feather development. Contemporary gene flow between King Island scrubtit subpopulations is unlikely, with further field monitoring required to quantify the fitness consequences of its small effective size, low genetic diversity and high inbreeding. Evidence-based conservation actions can then be implemented before the taxon goes extinct.