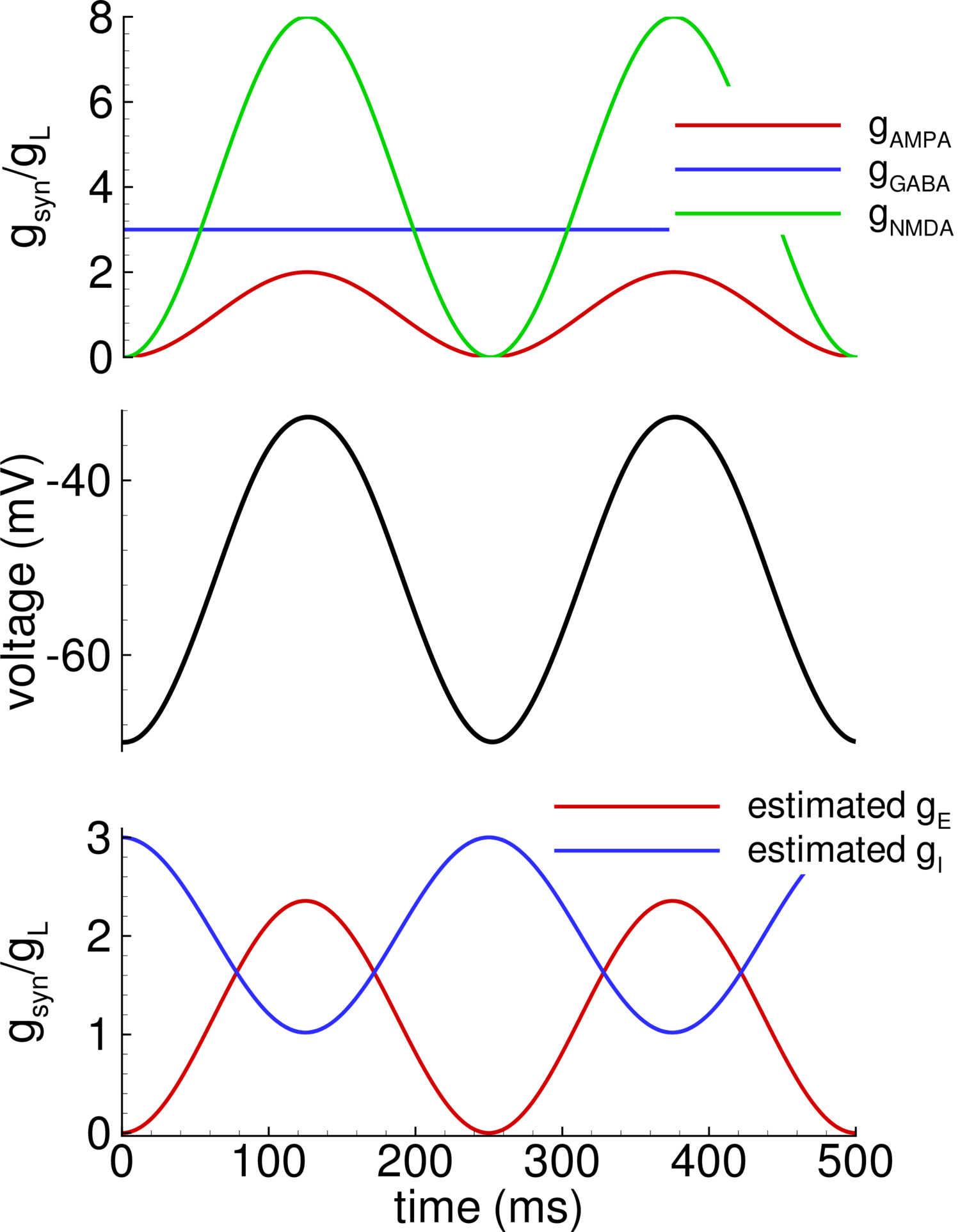
REVIEW This paper proposes a reevaluation of the impact of NMDA conductance recruitment during visual activation of V1 cortical neurons in vivo and questions the validity of previous decomposition methods used by different authors to dissect out the timing and the influence of excitatory and inhibitory synaptic components in visual responses. On the basis of simple conductance-based simulations, they point out the fact that inhibitory contribution may have been under-estimated during phases of strong depolarization, due to the absence of the NMDA component in the decomposition. They conclude that this over-simplification in the decomposition puts in jeopardy the existence of push-pull organization in Simple cells. This report was written with Dr Cyril Monier. The methodological issue raised in this commentary paper is certainly a valid one, but the conclusions of the author remains largely exaggerated if not unsubstantiated. On the one hand, it is a fact that most conductance decompositions of synaptic responses do no account for the contribution of NMDA receptor activation, which may indeed participate to the expression of functional properties of sensory cortical neurons in vivo. On the other hand, the functional impact of this hypothetical recruitment is critically linked to the assumed ratio between NMDA and AMPA excitatory components, and unfortunately the author does not provide new experimental evidence that would justify his claim. In a way the present paper pushes already open doors and it would be unfair to assume that this issue was totally ignored by the pioneers of conductance decomposition of visual responses in vivo. This problem was partially tackled in the PhD thesis of Cyril Monier and the choice of voltage clamp measurements provided a way of minimizing the masked contribution of NMDA currents triggered in current clamp experiments. Cyril Monier, in his thesis, mentioned explicitly the fact that ”it is possible that in the presence of strong excitatory conductances, one underestimates the inhibitory conductance, by not taking into account voltage-dependent and NMDA conductances recruited by the global excitatory process”. We review below in succession a few factors that may weaken significantly the claims of the author: - Voltage clamp vs Current Clamp: It is important to distinguish in the published literature between measurements made in voltage clamp (VC) (Fregnac’s team; Borg-Graham et al, 1996; 1998; Monier et al, 2003; 2008) and current clamp (CC) (the later work of Ferster, Hirsch, Priebe’s teams among others: Anderson et al, 2000; Priebe et al, 2005). Not only do the membrane time constants differ between the two recording modes, but the local depolarization state of the recorded neuron is better controlled in VC mode than in CC mode (in spite of imperfect space clamp in vivo). Consequently in this latter mode (VC), the possible impact of NMDA recruitment can be ignored for holding potentials more negative than -40 mV (where only 10% of NMDA receptors are activated). No. The authors should provide distinct simulations for each of the recording modes (CC and VC). - Linearity (or not) of IV curves: Monier et al (2008) report that IV curves (for voltage values between -90 and -40 mV) are more linear when measured during the evoked state than during the ongoing state. For this range of potentials, NMDA activation will correspond to a weak negative conductance component with a linear impact. If inhibitory conductances are strong (which we reported in vivo), the effect can be neglected. The authors should provide distinct simulations for different level of inhibitory conductances. - Amplitude of NMDA conductances : The choice made by the author of the balance between AMPA and NMDA in the proposed simulations is very high (compared to Stern et al, 1992). This raises the question of the criticality of that ratio, and whether the impact of NMDA is a linear function of this ratio. This may constitute a side issue that could be studied parametrically through additional simulations. The main argument in favor of a strong NMDA component in cat cortex in vivo comes from an abstract of Kevin Fox (1990), where the iontophoretic effect of NMDA blocker (D-APV) is described as mostly developmental (before and at the peak of the critical period) and layer-dependent, being stronger in superficial layers. In granular and deep layers (IV, V, and VI), D-APV affected the visual response in young animals but only spontaneous activity in older animals. Fox study does not comfort the present proposal since the push-pull organization is the hallmark of Simple cells in layer 4. Note also that the fact that anti-correlated excitatory and inhibitory conductances can be observed in Simple Cells for other types of stimuli than gratings, such as dense noise (Baudot et al, 2013), whose kinetics are too fast for NMDA recruitment, remains an additional argument for the existence of push-pull organization in cat V1. Note finally, that the fact that the push-pull organization in Simple cells is observed only in the cat and not in the rodent visual coretx, suggests that this organization results from a structural anlage which is specific of the species under study rather being the trivial consequence of a methodological artifact (the consequence of which should be the same in both studies). - GABA-B involvement : Since the authors are looking for a more exhaustive description of the impact of each possible neurotransmitter, it could have been in the scope of this paper to try to separate also GABA-A and GABA-B influences. This may be particular relevant for the type of stimulation used for the simulations. A drifting grating triggers only a transient activation of the GABA-A, which because of different time constants disappears a few tens of ms after the stimulus onset. Iontophoretic experiments by Albus et al showed a clear temporal dissociation of the effect on visual responses. A more complete study may show that two components can be distinguished in inhibition, one dynamically related to the phase of the stimulus (in an anti-phase fashion in simple cells) and another one acting as a non-specific dc component. But without added experimentation, this discussion will remain purely academic. RESPONSE We thank the editor for the choice of such proper reviewer for our Commentary and reviewer for careful consideration and insightful comments. We agree that the style of the Commentary should not be as if the issue was not considered before, thus we have corrected the text in the light of this aspect. Regarding the main conclusion, it is still the same after our careful consideration of the critics of the reviewer (see Supplementary Material), thus in the Commentary we have kept the same Figure and added some remarks in the text that are supported by figures given in Supplementary Material. SUPPLEMENTARY MATERIAL Voltage clamp vs Current Clamp The voltage-clamp (VC) and current-clamp (CC) modes give similar estimations. We illustrate this point by the Suppl. figures [F1] and [F2]. Linearity (or not) of IV curves Regarding the dependence of the estimation errors on the level of inhibition, we show (compare Suppl. fig. [F3] with [F1]) that the absolute value of the error does not depend on gGABA. Nontrivially, for the range of potentials more negative than -40 mV, where NMDA activation corresponds to a weak negative conductance, the error of inhibitory conductance estimation is large, as seen in Suppl. fig. [F4]. Explanation of this effect follow from the voltage-dependence of NMDA-current, fNMDA(V) (V − VE), shown in Suppl. fig. [F45]. A linear approximation of the current between the hold voltage levels, for instance, Vh¹ = −70 mV and Vh² = −40 mV, corresponds to negative conductance and an effective reversal close to VI. That is why, NMDA-current contaminates more gI than gE. The method is perfect in respect of gI estimation for the case of Vh² = 0, however it gives gE close to gAMPA, ignoring contribution of gNMDA. Usage of the hold voltage equal to the reversal potential of glutamatergic currents can be recommended, however, as known, it might require additional tricks to improve space-clamp. Amplitude of NMDA conductances The underestimation of inhibitory conductance depends on the magnitude of NMDA conductance. The dependence is shown in Suppl. fig. [F5]. In order to justify the ratio of NMDA versus AMPA conductance, set to be 4 in all simulations except those for Suppl. fig. [F5], we have considered experimental data from Stern et al. (1992). The data is well approximated by the profiles of the conductance components shown in Suppl. fig. [F6], which is seen from comparison of reproduced EPSCs shown in Suppl. fig. [F7]B with the experimental figure 12A from Stern et al. (1992) and reproduced in Suppl. fig. [F7]A. The AMPA-component dominates at -100 mV, whereas the NMDA-component is the most pronounced at +20mV, which is observed in both experiment and model. The ratio of the amplitudes of the components is almost the same in the experiment and model. This ratio is equal to 4, as in Fig. 1 of the Commentary and Suppl. fig. [F6]. Further, with this ratio kept, we changed the shape of presynaptic stimulus from pulse to sinusoidal (Suppl. fig. [F8]). In spite of the evidence that in the case of pulse stimulation the maximum of AMPA-conductance is much bigger than that for NMDA, the sinusoidal long-lasting stimulus results in the conductance ratio close to 4. This fact justifies the simulations described in Commentary and in this Response. Similar ratio of NMDA-versus-AMPA conductances has been revealed in our recent studies of interictal discharges in the combined slices of hippocampus and entorhinal cortex of rats (Amakhin et al., 2016). In this study the estimations of gAMPA, gGABA and gNMDA were performed from multi-level recordings in VC-mode. Estimations of gE and gI with conventional method have shown not qualitatively but quantatively different results. Push-pull organization The push-pull organization (Troyer et al., 1998, Fregnac and Bathellier, 2015) may result in antiphase of gE and gI, or may be less pronounced, not resulting in the antiphase. Nevertheless, the qualitative behavior of the conductances is an important feature to reproduce in computational models of the primary vision. However, we think that the antiphase of gE and gI in cats has not been well proved experimentally yet, because of possible contamination of conductance estimations by NMDA effect. Our Commentary pays attention to this problem and calls to improve the method of conductance estimation. We know from Liu et al. (2010) that in rodents EPSC and IPSC recorded at -70 mV and 0 in response to moving gratings are in antiphase, corresponding to in-phase course of gE and gI. According to our study, this derivation is correct, as follows from Suppl. fig. [F4] for Vh² = 0. Unfortunately, we do not know similar recordings in cats. GABA-B involvement GABA-B conductance does not so strongly depend on voltage as NMDA. That is why, it should be approximated as voltage independent. Together with AMPA and GABA, there are three voltage independent components. Unfortunately, without any additional assumptions on different kinetics, it is impossible to evaluate more than 2 such components. This issue is discussed, in particular, in Chizhov et al. // Front.Cell.Neurosc. (2014). Effect of noise In addition, we have considered the influence of noise, important to compare the methods of conductance estimation in VC and CC modes. We show that the noise does not dramatically affect the estimations in VC-mode (Suppl. fig. [F9]), whereas it does in CC-mode (Suppl. fig. [F10]), if noting quite different amplitudes of noise in these simulations. Alternative method of conductance estimation Better method of conductance estimation with explicit consideration of NMDA-component require recordings at 3 levels of the hold voltage in VC-mode. Its quality is seen from Suppl. fig. [F9]. Unfortunately, the method shows much worse precision in the CC-mode (Suppl. fig. [F10]). In VC-mode, the means of estimated gAMPAEst, gGABAEst and gNMDAEst are equal to the exact gAMPA, gGABA and gNMDA. The variation of gGABAEst due to noise in the 3-level method is smaller than not only the variation of gI but also the error of gI relative to gGABA in the 2-level method, as seen from Suppl. fig. [F11]. Conclusion On a base of the above analysis we may recommend for gE and gI estimations to use 2-level method in VC-mode with the hold voltages close to the reversal potentials of GABAergic and glutamatergic currents. For estimation gAMPA, gGABA and gNMDA we recommend the 3-level method in VC mode with the hold voltages -70, -40 and 0 mV. METHODS Neuron model We consider leaky neuron equation model with the AMPA, GABA and NMDA-receptor mediated synaptic currents: C {dV \over dt}&=&-g_L(V -V_L)+g_{AMPA}(t) (V_E-V ) +g_{GABA}(t) (V_I-V )\\ &+&g_{NMDA}(t) f_{NMDA}(V) (V_E-V ) + I + \sigma_V g_L \eta(t)\nonumber where C is the membrane capacity; gL is the membrane time constant; VL, VE, VI are the reversal potentials of the leak, excitatory and inhibitory currents; I is the current through electrode; fNMDA(V)=1/(1 + Mg/3.57exp(−0.062 V)) is the voltage dependence function of NMDA-conductance with the magnesium concentration Mg; η(t) is the gaussian white noise with zero mean and unity dispersion. Estimation of gE and gI in VC-mode Estimations of gE(t) and gI(t) require two recorded currents I₁(t) and I₂(t) at two voltage levels Vh¹ and Vh². The result is g_I(t)&=&(-G_L(V_h^1-V_L)(V_h^2-V_E)+G_L(V_h^2-V_L)(V_h^1-V_E) \nonumber \\ &-&I_2(t)(V_h^1-V_E)+I_1(t)(V_h^2-V_E)) \\ &/&((V_h^1-V_I)(V_h^2-V_E) -(V_h^2-V_I)(V_h^1-V_E)), \nonumber g_E(t)&=&(-G_L(V_h^1-V_L)(V_h^2-V_I)+G_L(V_h^2-V_L)(V_h^1-V_I) \nonumber \\ &-&I_2(t)(V_h^1-V_I)+I_1(t)(V_h^2-V_I)) \\ &/&((V_h^1-V_E)(V_h^2-V_I) -(V_h^2-V_E)(V_h^1-V_I)) \nonumber Estimation of gE and gI in CC-mode In CC-mode, estimations of gE(t) and gI(t) require two recorded voltage traces V₁(t) and V₂(t) calculated for two input currents I¹ and I² according to eq. ([e1]) with known functions of gAMPA(t), gGABA(t) and gNMDA(t). Then, we assume that the voltages approximately satisfy to the equations with unknown gE and gI: C {dV_1 \over dt}&=&-g_L(V_1 -V_L)+g_E(t) (V_E-V_1 ) +g_I(t) (V_I-V_1 ) + I_1 \\ C {dV_2 \over dt}&=&-g_L(V_2 -V_L)+g_E(t) (V_E-V_2 ) +g_I(t) (V_I-V_2 ) + I_2 where C and gL are supposed to be known. The conductances gE and gI are obtained as a solution of the system of algebraic linear equations ([e131], [e132]). Estimation of gAMPA, gGABA and gNMDA in VC-mode Estimations of gAMPAEst, gGABAEst and gNMDAEst require three currents I₁(t), I₂(t) and I₃(t) calculated with eq.([e1]) at three voltage levels Vh¹, Vh² and Vh³. The conductances gAMPAEst, gGABAEst and gNMDAEst are obtained for each time step as a solution of the system of algebraic linear equations: g_L(V_h^1 -V_L)&-&g_{AMPA}^{Est}(t) (V_E-V_h^1 )-g_{GABA}^{Est}(t) (V_I-V_h^1 ) \nonumber \\ &&-g_{NMDA}^{Est}(t) f_{NMDA}(V_h^1) (V_E-V_h^1 ) = I_1(t), \\ g_L(V_h^2 -V_L)&-&g_{AMPA}^{Est}(t) (V_E-V_h^2 )-g_{GABA}^{Est}(t) (V_I-V_h^2 )\nonumber \\ &&-g_{NMDA}^{Est}(t) f_{NMDA}(V_h^2) (V_E-V_h^2 ) = I_2(t), \\ g_L(V_h^3 -V_L)&-&g_{AMPA}^{Est}(t) (V_E-V_h^3 )-g_{GABA}^{Est}(t) (V_I-V_h^3 )\nonumber \\ &&-g_{NMDA}^{Est}(t) f_{NMDA}(V_h^3) (V_E-V_h^3 ) = I_3(t). Estimation of gAMPA, gGABA and gNMDA in CC-mode In CC-mode, estimations of gAMPA, gGABA and gNMDA require three recorded voltage traces V₁(t), V₂(t) and V₃(t) calculated for three input currents I¹, I₂ and I³ according to eq.([e1]) with known functions of gAMPA, gGABA and gNMDA. Then, gAMPAEst, gGABAEst and gNMDAEst are obtained for each time step as a solution of the system of algebraic linear equations C {dV_1 \over dt}&+&g_L(V_1 -V_L)-g_{AMPA}^{Est}(t) (V_E-V_1 )-g_{GABA}^{Est}(t) (V_I-V_1 ) \nonumber \\ &&-g_{NMDA}^{Est}(t) f_{NMDA}(V_1) (V_E-V_1 ) = I_1(t), \\ C {dV_2 \over dt}&+&g_L(V_2 -V_L)-g_{AMPA}^{Est}(t) (V_E-V_2 )-g_{GABA}^{Est}(t) (V_I-V_2 )\nonumber \\ &&-g_{NMDA}^{Est}(t) f_{NMDA}(V_2) (V_E-V_2 ) = I_2(t), \\ C {dV_3 \over dt}&+&g_L(V_3 -V_L)-g_{AMPA}^{Est}(t) (V_E-V_3 )-g_{GABA}^{Est}(t) (V_I-V_3 )\nonumber \\ &&-g_{NMDA}^{Est}(t) f_{NMDA}(V_h^3) (V_E-V_h^3 ) = I_3(t), \\ where C and gL are supposed to be known. Synaptic kinetics The synaptic conductances were described following Chizhov (2013) , i.e. as follows g_{AMPA}(t)&=&_{AMPA} ~m_{AMPA}(t), \\ g_{NMDA}(t)&=&_{NMDA} ~f_{NMDA}(V(t)) ~m_{NMDA}(t), where mAMPA(t) and mNMDA(t) are the non-dimensional synaptic conductances, each being approximated by the second order ordinary differential equation: \tau_1 \tau_2 {dt^2} + (\tau_1+\tau_2) {dt} + m = \tau \varphi(t), \tau&=&{(\tau_1-\tau_2)}/ \bigl( ({\tau_2}/{\tau_1})^{\tau_2/(\tau_1-\tau_2)} - ({\tau_2}/{\tau_1})^{\tau_1/(\tau_1-\tau_2)} \bigr), \\ &&~~~~\tau_1\neq \tau_2, {{\tau_1}{e}}, ~~. \nonumber Here φ(t) is the presynaptic firing rate; $_{AMPA}$ and $_{NMDA}$ are the maximum conductances, τ₁ and τ₂ are the rise and decay time constants. The time scale τ in the form of eq.([e254]) provides independence of the maximum of g(t) on τ₁ and τ₂ in the case of stimulation by a short pulse of φ(t). References Amakhin, D.V., Ergina, J.L., Chizhov, A.V., and Zaitsev, A.V. (2016) Synaptic conductances during interictal discharges in pyramidal neurons of rat entorhinal cortex. Frontiers in Cellular Neuroscience 10:233, DOI: 10.3389/fncel.2016.00233. Chizhov, A.V. (2014) Conductance-based refractory density model of primary visual cortex, J. of Comp. Neuroscience, 36(2): 297-319. Chizhov, A.V., Malinina, E., Druzin, M., Graham, L.J., and Johansson, S. (2014) Firing clamp: a novel method for single-trial estimation of excitatory and inhibitory synaptic neuronal conductances. Front. Cell. Neuroscience 8: 86. Fregnac, Y., and Bathellier, B. (2015) Cortical Correlates of Low-Level Perception: From Neural Circuits to Percepts. Neuron 88, 110-126. Liu, B.H., Li, P., Sun, Y.J., Li, Y.T., Zhang, L.I., and Tao, H.W. (2010) Intervening inhibition underlies simple-cell receptive field structure in visual cortex. Nat. Neurosci. 13, 89–96. Troyer, T.W., Krukowski, A.E., Priebe, N.J., and Miller, K.D. (1998) Contrast invariant orientation tuning in cat visual cortex: thalamocortical input tuning and correlation-based intracortical connectivity. J. Neurosci. 18, 5908–5927.